
פוסט אורח מאת שרון לוי
בסדנת הקיץ של "מדע הנתונים לטובת הכלל״ אנחנו עובדים עם עמותת ״דף חדש״ לניתוח פסקי דין שקשורים להסדרי חוב. חלק מהמסמכים קיימים בצורת doc או pdf שאפשר למשוך מהם את הטקסט ישירות כמחרוזת. אבל חלקם הם תמונה סרוקה של מילים מודפסות, ויש צורך בהמרה של התמונה למילים.
טכנולוגיה להמרת קבצים סרוקים נקראת OCR – Optical Character Recognition והיא קיימת כבר זמן רב (ותיקי התחום זוכרים את MNIST ולפניו את NIST, שנולדו סביב 1994). תוכנות שכאלו לרוב מתמודדות בהצלחה עם המרה של מסמכים סרוקים, אך לעיתים צצות בעיות וטעויות שונות, בפרט במסמכים בעברית, ועוד יותר במסמכים משפטיים, כפי שנראה מיד.
השלב הראשוני כדי להתמודד עם טעויות שכאלו הוא להבין היכן הטעויות מלכתחילה. במקרה שלנו, רצינו תחילה למפות את אותן הטעויות הנפוצות מסך המילים הסרוקות במסמכים שלנו. לשם כך, תחילה בחרנו אקראית מדגם גדול יחסית של 50 קבצי טקסט מומרים. 50 הקבצים האלו הכילו 48,397 מילים בסך-הכל (ובהן 7853 מילים ייחודיות). בהמשך, בדקנו האם כל אחת מהמילים הללו נמצאת במילון עברי מקיף אשר כולל, בין היתר, הטיות שונות, מילים הן בכתיב מלא והן חסר, נטיות שונות לפעלים וכן הלאה.
בדיקה ראשונית זו העלתה כי 4,104 מילים, או כ-8.3% מסך המילים במסמכים שלנו, לא נמצאות במילון. את הקבוצה הזאת ניסינו לאפיין כדי להקטין את מספר השגיאות. הנה התובנות שהגענו אליהן:
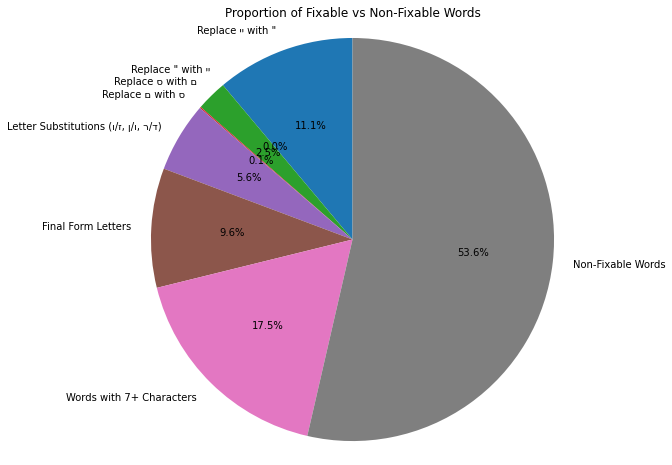
מילים בז׳רגון
למרות שחלק מהמילים לא נמצאו במילון, הן דווקא כן מילים תקינות בעברית. השתמשנו במילון מקיף, אבל בפסקי הדין שנפוצים בפרויקט שלנו יש ז'רגון משפטי, שימוש נפוץ בשמות של פסקי-דין, תאריכים עבריים וראשי-תיבות. לכן, החלטנו להרחיב את המילון עם שמות של פסקי-דין (כמו: אלקצאצי), מונחים משפטיים (אבעיה, דא עקא וכן הלאה), ראשי-תיבות נפוצים (פס"ד, למשל), תאריכים עבריים ושמות ישראלים וערבים פופולאריים. בסוף השלב הזה, נותרנו עם 2069 מילים או 4.23% מילים שגויות מסך המילים בקבצים שלנו.
תקלות OCR
בשלב השני, לאחר שנותרנו עם מילים שגם לא במילון וגם באמת לא מילים תקינות בשפה – יכולנו לבחון את השגיאות הנפוצות שנובעות מתהליך ה-OCR עצמו. גילינו מיד שהטעויות הנפוצות שחוזרות עליהן נובעות, באופן אינטואיטיבי, מתווים דומים ויזואלית:
- יי (פעמיים האות י׳) במקום " (גרשיים)
- ם (מם סופית) במקום ס'
- ז' במקום ו'
- אותיות סופיות שמוחלפות בגירסה הלא-סופית של אותה אות: מ׳ במקום מם סופית, ובדומה עבור נ׳ וגם פ׳.
- וכן הלאה.
מחיקת רווחים
שגיאה נפוצה נוספת היא איחוד של שתי מילים תקניות למילה אחת שגויה: לדוגמה, ביטוי כמו "יוביל לביטול" הפך לאחר ה-OCR ל-"יוביללביטול".
לתיקון של מקרים כאלה פיתחנו את היורסיטיקה הבאה:
- סינון של מילים עם 7 אותיות או יותר
- מעבר על הרצף והפרדה שלו בכל נקודות האמצע (לפי הדוגמה, ננסה את: ״יוב יללביטול״, ״יובי ללביטול״, ״יוביל לביטול״ וכן הלאה)
- לכל אפשרות, שיערוך כמה היא נפוצה
- בחירת האפשרות הנפוצה ביותר
בפועל, כמו שקורה לא פעם, הבנו שבקורפוס שלנו יש מעט מקרים כאלה ופשוט יותר לתרגם אותם בעזרת מילון קשיח (בלי לקודד אלגוריתם).
מתוך 4104 רצפים שגויים שנותרו בתחילת שלב זה, היוריסטיקה הצליחה להוריד את מספר הרצפים השגויים מ 4104 (שלא נפתרו על-ידי השלבים הקודמים) ל-1096 מילים שלא במילון, או 2.6% מכלל המילים בטקסט.
זה כבר מספיק טוב לצרכינו, ולא המשכנו לטייב עוד. אפשרות לשיפור נוסף יכולה להיות בדיקה של אינטראקציה בין טעויות, למשל: איחודי מילים שגם מכילים יי (יוד כפולה) במקום " (גרשיים); מילים עם שתי החלפות שונות – למשל, "דמיון" שנהפך ל-"זמיונ", (זאת אומרת גם ה-ד' נהפכה ל-ז' וגם ה-ן ל-נ'), וכן הלאה.
לסיום, הנה ההתפלגות של השגיאות שונות בטקסטים שלנו:
כתיבת תגובה