-
Economics of a BESS for EV charging
Thinking about adding a battery energy storage system (BESS) to your EV charging station? The economics can be surprisingly complex, and what seems intuitive might not always be the most profitable path.
Our digital twin tool can accurately model the real-world performance and return on investment (ROI) of a battery purchase, and our simulations often reveal fascinating, less-than-intuitive results.Here's a look at what we tested:
We started with a baseline: a busy charging station receiving 310 kW of power from the grid. It has a mix of dual-nozzle chargers: 150/90/70/70kW. The energy cost is on ToU schedule with higher rates 5pm-11pm. The energy price (to drivers) is also on a ToU schedule, peaking between 1pm and 6pm.
Then, we simulated the impact of adding three different battery configurations:
Small Battery: 50 kWh, 1C rating. This option is cheaper upfront, but its higher C-rating and smaller size make it more expensive per kW delivered.
Medium Battery: 200 kWh, 0.5C rating.
Big Battery: 372 kWh, 0.5C rating.
We modeled a marginal cost of $450/kWh for the small battery and $375/kWh for the others. When we ran these scenarios against realistic driver behavior, the results were compelling:
The baseline station generated an average profit of $1618 per day. This is the difference between the price of selling energy and the cost of buying it (each transaction computed with the applicable rate at the time it was executed). Adding the small 50 kWh battery increased daily profit by an additional $129. This translates to an impressive 70.8% cash-on-cash return or a 19.8% annualized rate of return. We modeled the financing with a 5-year, 3% interest loan.
The biggest 372 kWh battery added $435 per day, yielding a 71.3% cash-on-cash return or a 19.9% annualized RoR.
However, the surprising winner in pure dollar value was the medium 200 kWh battery. This option generated the highest returns with a 77.7% cash-on-cash return or a 22.9% annualized RoR.
But RoR isn't the only factor. Our digital twin also models many other parameters, allowing us to compute a "driver experience score." This metric reflects customer satisfaction and loyalty. The baseline station scored 51. Both the small and medium battery configurations improved this to around 58. The clear winner for driver experience was the big 372 kWh battery, achieving a score of 63. This means higher customer satisfaction and potentially more returning drivers.
This kind of analysis is crucial because different businesses value different aspects – some prioritize maximum financial return, while others might focus more on enhancing the driver experience to build loyalty. Our digital twin helps you make informed, customized investment decisions that align with your specific goals for your EV charging infrastructure. If you'd like a similar comparison tailored to your station's unique conditions and customer base, get in touch! -
קרובים קרובים
שחר לוטן העלה שאלה מעניינת בטוויטר: האם יש בישראל יישובים קרובים בקו אוירי (פחות מ-2 קילומטרים), אבל הנסיעה ביניהם אורכת זמן רב משמעותית? כדוגמה, הוא ציין את כחל וחוקוק (זה בגליל), שהמרחק האווירי ביניהם הוא כ-1800 מטרים, אך הנסיעה בכביש ביניהם עולה על 20 קילומטרים.
כדי לבחון את השאלה הזו באופן שיטתי, כתבתי קוד שמתשאל את מפות גוגל. הוא מחלץ מרחקי נסיעה וזמני נסיעה בין צמדים של יישובים בישראל. שאילתות עולות כסף וגם מחממות את הגלובוס, ולכן חוץ מסף מרחק של 2 ק״מ, סיננתי גם לפי אוכלוסיה שקטנה מ-1200 תושבים (על פי נתוני למ"ס משנת 2021). ההנחה היא כי ליישובים גדולים יותר יש בדרך כלל רשת כבישים מפותחת יותר, ולכן סביר להניח שהפער בין המרחק האווירי למרחק הנסיעה יהיה קטן יותר.
במהלך הבדיקה, נמצא צמד יישובים שמציג פער משמעותי אף יותר מהדוגמה של שחר: ראס עלי וסוועדא חמירה, הממוקמים באזור הסוללים. המרחק האווירי ביניהם הוא כ-1400 מטרים בלבד, אך מרחק הנסיעה בכביש עומד על כ-21.6 קילומטרים. אמנם מפות גוגל מצביעות על מסלול קצר יותר דרך שטחים חקלאיים, אבל הוא לא סלול ולכן איטי יותר.

בנוסף לצמד זה, יש עוד מספר צמדים של יישובים קרובים/רחוקים: צורית ושורשים בגוש שגב ממערב לכרמיאל (שעלה בשרשור בטוויטר); גדעונה ונורית בגלבוע; וחוסניה ומכמנים ממזרח לכרמיאל. עם זאת, מבין כל הצמדים שנבדקו, רק שניים הראו מרחק נסיעה העולה על 20 קילומטרים: כחל/חוקוק וראס עלי/סוועדא חמירה.
מעבר למרחק הנסיעה, אפשר גם לבחון את היעילות היחסית של הנסיעה על ידי חישוב "המהירות האפקטיבית" – כלומר, חלוקת המרחק האווירי בזמן הנסיעה. במימד הזה בולטים במיוחד הצמדים משמר השרון וכפר חיים. המרחק האווירי ביניהם הוא כ-400 מטרים במישור, ועם זמן נסיעה של כ-9.5 דקות, כלומר מהירות אפקטיבית של כ-2.7 קילומטרים לשעה – נמוך משמעותית ממהירות הליכה. צמד נוסף ראוי לציון הוא מורן וחזון, הממוקמים מעט ממזרח לכרמיאל, שם המהירות האפקטיבית היא כ-4 קילומטרים לשעה, אבל בתוואי שטח שלא מאפשר קיצור בהליכה. מצב דומה קיים גם בין גיתה ללפידות, שניהם מצפון לכרמיאל.
בשרשור בטוויטר עלו דוגמאות נוספות: יטבתה ושחרות (6 ק״מ באויר או 44 ק״מ בכביש); הפינה של מעלות שקרובה תיאורטית לאבירים (ואבירים); והפינה של חיפה שקרובה תיאורטית לטירת הכרמל (וטירת הכרמל); וכן נקודות ליד קו הוורונוי בין שכונות באותה העיר.
במקרה של טירת הכרמל אפשר לשאול שאלה אחרת: יש שם שכונה בשם רמת בגין. גם בחיפה יש שכונה באותו השם, ומרחקן האוירי פחות מקילומטר. יש דוגמאות דומות בעוד מקומות בארץ? אולי נושא לפוסט הבא.עוד שאלות ואנליזות? דברו איתי
-
Smart cat fountain
Cats have an undeniable love for freshly-run water. Whether it’s investigating leftover cups on the dinner table or peeking into the toilet, they’ll go to great lengths for that crisp, flowing taste. But what if there were a smarter, cleaner way to satisfy their cravings?
The Smart Water Bowl Solution With a Zigbee-controlled irrigation controller and a motion sensor, you can set up a clever system to provide fresh water right when your cat wants it. Here’s how it works:

Placement: The motion sensor is positioned near the food bowl. When the cat approaches, the bowl is re-filled.

Controlled Water Flow: The irrigation controller activates, filling a water bowl with fresh water. The water flow is slowed to a gentle trickle using a drip irrigator. The cats love this – sometimes you'll see them lick the drops as they're falling down.
Safety Measures:
The water stops automatically after 30 seconds, avoiding waste or overflow.
In addition, a software timer enforces a minimum two-hour interval between activations.
For the sensor to really focus on the area near the bowl, and not fire on every random movement in the vicinity, you need to restrict the range of detection. Luckily, I was using a cheap PIR sensor, which can be easily blocked by a piece of plastic or duct tape. I found an unused food container, and applied two-sided tape to place the sensor inside:

Then I cut out a piece of the cover to create a peephole:

This box can be easily placed so it watches the food bowl and nothing else.
-
Bathroom Led Alert
Ending Shower Wars with Smart Tech: The kids love long showers. And who can blame them? The hot water, the steam, the solitude. But while they’re enjoying their spa-like experience, someone else might be outside… waiting. Tapping their foot. Sighing loudly. What’s a smart home enthusiast to do?
Here’s the solution: a visual alert system right inside the shower, controllable from the outside. Let’s break it down.
The Setup
Inside the bathroom: A programmable LED strip mounted near the shower.
Outside the bathroom: A push button that changes the light’s color inside.

Bonus feature: A door sensor to detect when the bathroom is (finally) free.
How It Works When someone’s waiting and feeling polite, they press the button once. The LED strip glows green inside the shower, subtly signaling: “Hey, take your time, but don’t forget I’m here.”

As patience wanes, another press turns the light yellow: “Okay, maybe start wrapping it up.”

A third press? The light turns red. No words needed. It’s shower-code for: “Seriously, time’s up.”

Finally, when the door sensor detects that the bathroom door opens, a speaker announces: “The bathroom is now vacant.” A small victory for smart tech and shared living spaces. And the kids? they love it.
Technical details: here is the automation file. It handles the logic above, as well as shadow clicks that happen to appear on MQTT right after the real click (it ignores them). Also, it sends the command to the LED strip twice – otherwise the hardware sometimes ignores it.
-
שינויים במאפייני טעינה
משרד התחבורה מפרסם כמה מכוניות מכל דגם קיימות על הכבישים בישראל. לכל דגם ידועה קיבולת הסוללה וגם הספק הטעינה המקסימלי. מה שמאפשר לחשב סטטיסטיקות ולהגיע לתובנות.
הסתכלתי על דגמים שמהם יש לפחות 1000 יחידות על הכביש בישראל, ובשתי נקודות זמן: אפריל 2023 למול דצמבר 2024.
נקודה מעניינת עלתה בהקשר של הספק טעינה מקסימלי. אמנם נכנסו השנה לשוק דגמים עם יכולות לטעינה מאוד מהירה, כמו איוניק 6 (234 קילוואט) ואקספנג (300 קילוווט!). אבל הם לא מוכרים במספרים גדולים. הדגם הנמכר ביותר ב-2024 הוא עדיין BYD ATTO3 עם הספק מקסימום של 86 קילוואט, והבאים ברשימה הם צ׳רי וגאומטרי, גם כן בטווחים של 70-90 קילוואט.
אז מה השורה התחתונה? אם נחשב את הערך החציוני, כלומר מספר שחצי מהמכוניות שנכנסות לטעינה מושכות יותר ממנו, וחצי מושכות פחות ממנו נקבל:
- בשנת 2023: 125 קילוואט
- בשנת 2024: 92 קילוואט
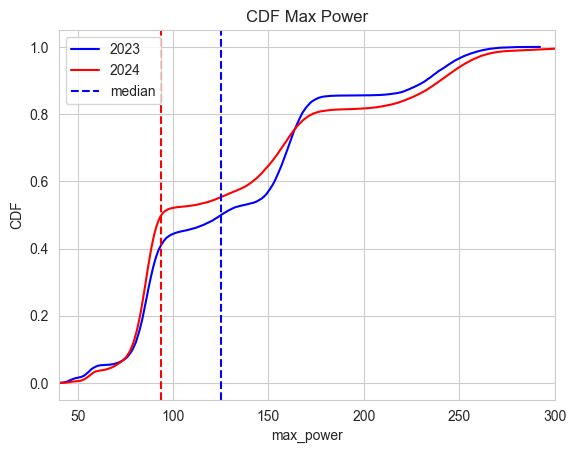
פרשנות: עם גדילה משמעותית במספרי החשמליות, השוק עובר מנהגים שהם early adopters וקונים מכוניות יוקרה, אל הנהגים הממוצעים יותר שקונים מכונית ״רגילה״.
ובמילים: מכונית אקראית על כבישי ישראל היום, מושכת הספק טעינה (מקסימלי) נמוך משמעותית מאשר היה לפני כשנה וחצי.
ומה לגבי קיבולת הסוללה? כלומר הגודל של ״מיכל הדלק״? גם כאן, יש חריגים בתחום העליון, כמו שוב האקספנג, שמגיע עד 92 קוט״ש. מדובר במספר מאוד מאוד גבוה בגזרת החשמליות (אם כי מבחינה אנרגטית זה שווה ערך לכ-10 ליטר בנזין, שזה מיכל דלק של קטנוע). אבל זה חריג, ורוב המכוניות – כולל טסלה – מסתפקות בכ-60 קוט״ש. הערך החציוני הוא 59 קוט״ש, והוא לא השתנה בין 2023 ל 2024.
רק להדגשה – זה יחסי ולא אבסולוטי. במספרים, יש יותר מכוניות חשמליות מכל הסוגים. בשנת 2024, אחד מכל ארבעה רכבים שנמכרו בישראל היה חשמלי. אז לא לפרש את מה שכתוב כאן כאילו יש פחות מכוניות יוקרה חשמליות מאשר בעבר. יש יותר. אבל החלק היחסי שלהן (מה סביר שתראו אם תפגשו מכוניות אקראית בכביש) יורד.
-
Vibration sensor to detect wet clothes in the washing machine
If the washing machine completes the cycle and the clothes stay inside, bad things could happen. At least this is what my wife tells me. So here is a guide to detect the event of a washing cycle and export it to Home Assistant. There, it could trigger all kinds of notifications – phone app, smart speaker announcement, and so on. Here, I'm using a simple indicator light. As a bonus, the same sensor can also figure out when the washer door is opened, and only then turn off the indicator light.
I can think of several ways to detect a washing machine cycle. You could power it with a smart socket that includes power metering, and detect the surge in power input; you could tape some kind of light sensor to the control panel so it sees when the appropriate indicator comes on; you could use a microphone to record the beeps it make, possibly with the help of some signal processing. I chose to use a vibration sensor. The advantage is that if you place it on the door, then it can also double as a door-opened detector. I used an Aqara Zigbee vibration sensor, and placed it on the door with two-sided tape. It sits next to the handle, and far from the hinge (to amplify the swing).

This sensor can detect one of two things: vibration and drop. The vibration is what you get when the machine is spinning. A "drop" is a sudden jolt, which could work to detect when the door is opening. But it doesn't appear quite like this in HA – see below. Actually, this sensor can also report how it's positioned, as angles on the X, Y, and Z axes, but I'm not using that, and I think that once it's on the door, these never change. Well, maybe if the washing tips over, but I'm not too worried about that.
Ideally, the vibration sensor would detect when the machine spins, and that is the last step of a washing cycle. So a simple solution to the problem would be an automation rule for something like "vibration event detected for more than 5 minutes". That's what I tried first, and it doesn't work. To see why, here is a chart of the "vibration" and "action" (drop) events over time, as the machine runs through its cycle:

There are several things going on here: first, there are some short periods during the cycle when the vibration sensor activates. Second, action events sometimes also register as a vibration event. What I found is that this sensor never sends an event that's shorter than 89 seconds, even if it's just a drop (I dropped it on the table to test). This probably has to do with the software on the device, and we'll need a way to work around it.
So the solution, at least on my Bosch machine, is a split rule that goes like this: you wait for two separate vibration events, each lasting at least 2:30 minutes, spaced no more than 30 minutes apart. Only after you have those, then you wait for the final spin of more than 5 minutes. When it happens, the machine is done and you can trigger the desired notifications. And once that happens, this is when you look for an "action" event, which will tell you when the door is open.
To make it work, I used two separate automations: one for counting how many short (2:30 minute) events occurred, and the second to wait for the final spin and door open. They communicate with each other using a helper counter.
For the indication device I chose a small USB night light connected to a smart USB switch. It's located centrally in the house so anyone could see it and know to at least open the washer door. Here is what it looks like:

And here is what happens when you open the washer door:
I must admit that this is not bullet-proof. Sometimes the machine is on a short program. Or maybe it's loaded with a single heavy item so it dances a lot. Or maybe the dryer on top of it is vibrating just enough to itch the sensor. But for the regular program we most use, it works.
Next, I will probably look into the approach of hearing the beeps. Probably a little harder (my plan is to attach a microphone to a Raspberry pi and do the signal processing on it). But if it works, it could also send alerts for microwave beeps, and maybe the doorbell or smoke detectors. We'll see. And we'll hear. Hope you found this useful!
-
Modifying a USB light for smart home applications

.I like USB-powered lamps. They're small and easy to place anywhere
:Especially the goose-neck clip-on version
They have a switch to turn it off and on, and choose the light intensity. It's all fine and well if you press it manually every time you want to read a book. But I'd like to control this light with some kind of smart switch, so the USB port which feeds it is either on or off, depending on the logic I define in Home Assistant.

The problem is the switch: once it turns off, bringing back the power won't turn it back on, unless you click it manually. So we need to modify it if we want it to turn on and off depending on just the availability of power in the USB port. Luckily, that's easy if you're not afraid of some soldering. Here's how.
You can pry open the switch, and what you'll see is this:

We have power coming in from the right, red and black, then the PCB which contains the clickers and the logic, and it then sends the power out to the illumination elements from the left. There are two elements (warm light and cool light), and it uses three wires: black, red, and white. I tested with a voltmeter what's happening exactly, but in the end I ignored the white.

There is very little spare wire to work with here, so the easiest is to chop off the whole block on both sides, and then strip the outer insulation to expose about 10cm of wires on both sides. Put white aside, we won't be touching it.

You then strip the inner insulation about 3 cm on all four wires. Twist together black and black. Twist together red and red. Put on a coat of solder. You should now be able to test and see the light comes on right when power is applied.

You can now apply heat-shrink insulation on the connections. The next task is to stuff it back into the case. Use a zip tie on either side to make sure the cable is not pulled out, and gently fold the wires so they fit. Use some tool to hold everything in place as you snap on the cover.

You can now push the cover into place, and there you have it – a USB LED light you can control externally!
-
Hello world!
Welcome to WordPress. This is your first post. Edit or delete it, then start writing!
-
תאורה לממ״ד
גם אני נפלתי בשגעון הבית החכם. איזה בעיות זה יכול לפתור? ובכן, הבעיה הנוכחית היא שכשמחכים בממ״ד לתום עשר הדקות, הילדים כל הזמן שואלים כמה זמן עבר (חלקם מספיקים להביא טלפונים וחלקם לא).
אז קניתי מנורת אוירה, שמפיצה אור בגוונים שאפשר לתכנת. חיברתי את התראות פיקוד העורף לתוכנת הניהול (שנקראת home assistant) בעזרת תוסף מדהים של עמית פינקלשטיין. וכתבתי סקריפט שמשנה את הגוון בהדרגה, מאדום ועד ירוק, במשך 10 דקות. כשהצבע ירוק, אפשר לצאת.
עכשיו נשאר רק להחזיר את החטופים.
-
טעויות נפוצות ב-OCR בעברית, ואיך להתמודד איתן

פוסט אורח מאת שרון לוי
בסדנת הקיץ של "מדע הנתונים לטובת הכלל״ אנחנו עובדים עם עמותת ״דף חדש״ לניתוח פסקי דין שקשורים להסדרי חוב. חלק מהמסמכים קיימים בצורת doc או pdf שאפשר למשוך מהם את הטקסט ישירות כמחרוזת. אבל חלקם הם תמונה סרוקה של מילים מודפסות, ויש צורך בהמרה של התמונה למילים.
טכנולוגיה להמרת קבצים סרוקים נקראת OCR – Optical Character Recognition והיא קיימת כבר זמן רב (ותיקי התחום זוכרים את MNIST ולפניו את NIST, שנולדו סביב 1994). תוכנות שכאלו לרוב מתמודדות בהצלחה עם המרה של מסמכים סרוקים, אך לעיתים צצות בעיות וטעויות שונות, בפרט במסמכים בעברית, ועוד יותר במסמכים משפטיים, כפי שנראה מיד.
השלב הראשוני כדי להתמודד עם טעויות שכאלו הוא להבין היכן הטעויות מלכתחילה. במקרה שלנו, רצינו תחילה למפות את אותן הטעויות הנפוצות מסך המילים הסרוקות במסמכים שלנו. לשם כך, תחילה בחרנו אקראית מדגם גדול יחסית של 50 קבצי טקסט מומרים. 50 הקבצים האלו הכילו 48,397 מילים בסך-הכל (ובהן 7853 מילים ייחודיות). בהמשך, בדקנו האם כל אחת מהמילים הללו נמצאת במילון עברי מקיף אשר כולל, בין היתר, הטיות שונות, מילים הן בכתיב מלא והן חסר, נטיות שונות לפעלים וכן הלאה.
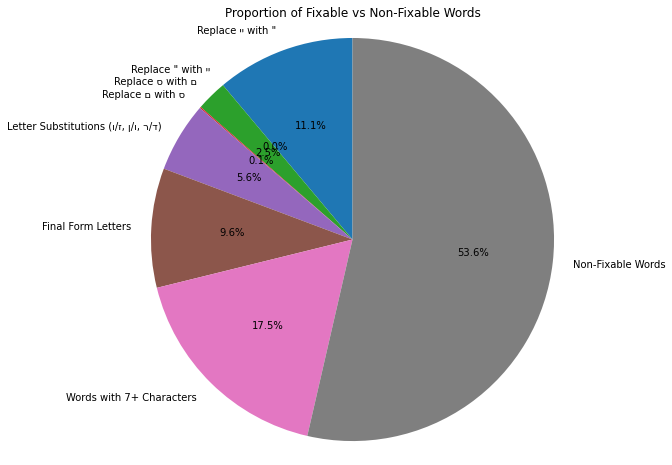
בדיקה ראשונית זו העלתה כי 4,104 מילים, או כ-8.3% מסך המילים במסמכים שלנו, לא נמצאות במילון. את הקבוצה הזאת ניסינו לאפיין כדי להקטין את מספר השגיאות. הנה התובנות שהגענו אליהן:
מילים בז׳רגון
למרות שחלק מהמילים לא נמצאו במילון, הן דווקא כן מילים תקינות בעברית. השתמשנו במילון מקיף, אבל בפסקי הדין שנפוצים בפרויקט שלנו יש ז'רגון משפטי, שימוש נפוץ בשמות של פסקי-דין, תאריכים עבריים וראשי-תיבות. לכן, החלטנו להרחיב את המילון עם שמות של פסקי-דין (כמו: אלקצאצי), מונחים משפטיים (אבעיה, דא עקא וכן הלאה), ראשי-תיבות נפוצים (פס"ד, למשל), תאריכים עבריים ושמות ישראלים וערבים פופולאריים. בסוף השלב הזה, נותרנו עם 2069 מילים או 4.23% מילים שגויות מסך המילים בקבצים שלנו.
תקלות OCR
בשלב השני, לאחר שנותרנו עם מילים שגם לא במילון וגם באמת לא מילים תקינות בשפה – יכולנו לבחון את השגיאות הנפוצות שנובעות מתהליך ה-OCR עצמו. גילינו מיד שהטעויות הנפוצות שחוזרות עליהן נובעות, באופן אינטואיטיבי, מתווים דומים ויזואלית:
- יי (פעמיים האות י׳) במקום " (גרשיים)
- ם (מם סופית) במקום ס'
- ז' במקום ו'
- אותיות סופיות שמוחלפות בגירסה הלא-סופית של אותה אות: מ׳ במקום מם סופית, ובדומה עבור נ׳ וגם פ׳.
- וכן הלאה.
מחיקת רווחים
שגיאה נפוצה נוספת היא איחוד של שתי מילים תקניות למילה אחת שגויה: לדוגמה, ביטוי כמו "יוביל לביטול" הפך לאחר ה-OCR ל-"יוביללביטול".
לתיקון של מקרים כאלה פיתחנו את היורסיטיקה הבאה:
- סינון של מילים עם 7 אותיות או יותר
- מעבר על הרצף והפרדה שלו בכל נקודות האמצע (לפי הדוגמה, ננסה את: ״יוב יללביטול״, ״יובי ללביטול״, ״יוביל לביטול״ וכן הלאה)
- לכל אפשרות, שיערוך כמה היא נפוצה
- בחירת האפשרות הנפוצה ביותר
בפועל, כמו שקורה לא פעם, הבנו שבקורפוס שלנו יש מעט מקרים כאלה ופשוט יותר לתרגם אותם בעזרת מילון קשיח (בלי לקודד אלגוריתם).
מתוך 4104 רצפים שגויים שנותרו בתחילת שלב זה, היוריסטיקה הצליחה להוריד את מספר הרצפים השגויים מ 4104 (שלא נפתרו על-ידי השלבים הקודמים) ל-1096 מילים שלא במילון, או 2.6% מכלל המילים בטקסט.
זה כבר מספיק טוב לצרכינו, ולא המשכנו לטייב עוד. אפשרות לשיפור נוסף יכולה להיות בדיקה של אינטראקציה בין טעויות, למשל: איחודי מילים שגם מכילים יי (יוד כפולה) במקום " (גרשיים); מילים עם שתי החלפות שונות – למשל, "דמיון" שנהפך ל-"זמיונ", (זאת אומרת גם ה-ד' נהפכה ל-ז' וגם ה-ן ל-נ'), וכן הלאה.
לסיום, הנה ההתפלגות של השגיאות שונות בטקסטים שלנו: